How I Audit a Legacy Rails Codebase in the First Week
My Rails codebase audit process: stakeholder interviews before code, Gemfile and schema before any tools, and a single-page triage as the deliverable.
Ally Piechowski · · Updated · 10 min read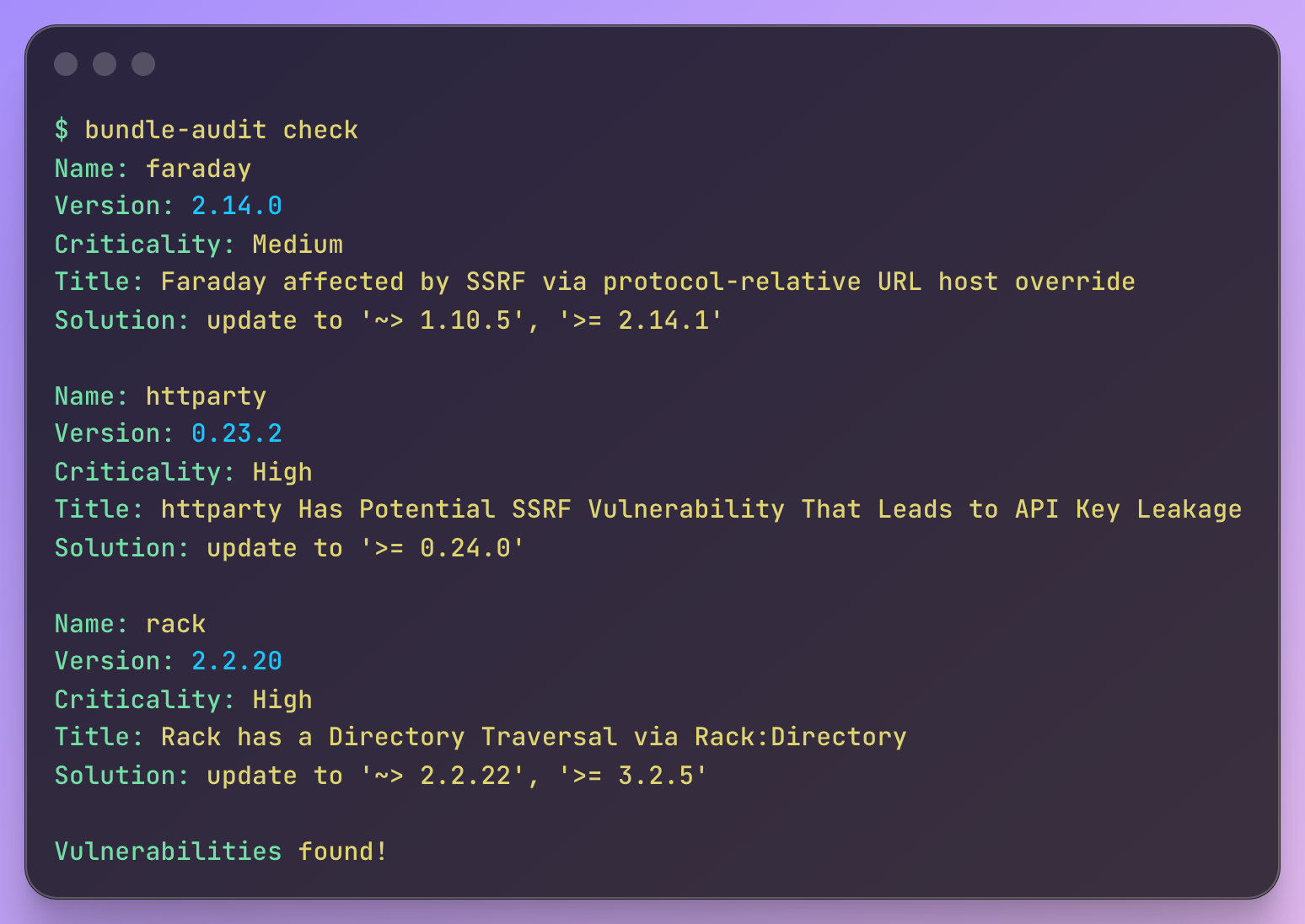
After doing this enough times, I’ve learned the first week isn’t about reading the code. It’s about reading the signals.
The client already has opinions about what’s wrong. They’re usually partially right and almost always wrong about why. Your job in week one is to separate what looks bad from what’s actually dangerous.
TL;DR: Start with people, not code. The tools come after you know what you’re looking for.
The client bashfully frames everything as “technical debt”, but the codebase actually seems a bit healthy at face value. The test suite runs, even if it’s a bit slow. Deploys happen automatically and regularly, even if they sometimes need a babysitter. But the real issue is that the engineer that gave notice last month wrote the entire checkout flow. They never documented it, and now the team is terrified to contribute to the flow. It’s good code, but it’s complex and underdocumented. The lack of knowledge sharing is the real problem, not the code itself.
Before You Clone the Repo: The Stakeholder Interview
The most diagnostic tool you have isn’t a gem.
You ask when the last time they deployed on a Friday was. They laugh. That laugh tells you more than any code metric could show you. It shows you that deploys are high stakes and that the team is living in fear of breaking production. On further investigation, you learn that there is no safe rollback procedure for deployment. If a deploy goes wrong, the team has to scramble to fix it in production. This is something static analysis won’t show you, but it’s also a critical signal of the codebase’s health.
Questions for developers:
- “What’s the one area you’re afraid to touch?”
- “When’s the last time you deployed on a Friday?”
- “What broke in production in the last 90 days that wasn’t caught by tests?”
Questions for the CTO/EM:
- “What feature has been blocked for over a year?”
- “Do you have real-time error visibility right now?”
- “What was the last feature that took significantly longer than estimated?”
Questions for business stakeholders:
- “Are there features that got quietly turned off and never came back?”
- “Are there things you’ve stopped promising customers?”
Reading the Gemfile, Schema, and Routes
You can form a working thesis in 30 minutes without running a single tool.
The transactions table had 122 columns. That number alone is a signal, but it starts to make a grim kind of sense when you see what’s in there. stripe_charge_id, wire_transfer_reference, ach_routing_number, paypal_transaction_id, every payment processor the company had ever integrated with, each with their own set of nullable columns, all crammed into one table. A wire transfer doesn’t need a stripe_charge_id. A Stripe charge doesn’t need an ach_routing_number. Most rows are mostly null.
The separation of concerns problem is bad, but fixable. The integer primary key is not. The table had been around since the company’s founding. They processed a healthy volume of transactions every day. I didn’t need to run a query to know they were probably sitting somewhere north of a billion rows. The maximum for a signed integer is about 2.1 billion. Nobody had thought about it because the app had always worked. I asked the CTO when they expected to hit that limit. He had no idea the limit existed.
Gemfile: count the gems, look for duplicated responsibilities (two auth systems, two file upload gems), note anything you can’t explain.
db/schema.rb: god tables with 30+ columns, missing indexes on obvious foreign key columns, dead tables with no model counterpart, integer primary keys in an old high-volume app (a quiet ID exhaustion timebomb).
config/routes.rb: total count and ratio of RESTful resources to custom one-off routes. 500 custom routes isn’t a style problem. It’s an architecture one.
Tools I Actually Run
SimpleCov reports 81% coverage. Looks healthy, right? Then you check which files have zero coverage: order.rb, payment.rb, subscription.rb. Three models that touch money have zero test coverage. The 81% was carried by hundreds of tests on utilities, views, mailers, and controllers.
Security: Run First, Non-Negotiable
bundle audit check --update
bundle exec brakeman --format html -o brakeman_report.html
Severity matters more than count. One critical CVE in an auth gem is a different problem than 20 low-severity advisories. With Brakeman, focus on confidence level and whether warnings are in high-traffic code paths.
Dependency Health
bundle outdated
bundle exec bundle_report compatibility --rails-version=7.2 # via next_rails gem
Name the EOL date. Rails 6.1 went EOL October 2024. In regulated industries, running an EOL version isn’t just tech debt, it’s a compliance liability. If the app is multiple versions behind, I map out what breaks in each version jump before estimating the work.
SLOC and Complexity
Honestly, cloc is mostly a gut check. I’m not looking for a specific number. I’m looking at where the lines are. If 80% of the codebase lives in app/models, that tells me something. Models doing all the heavy lifting usually means business logic tightly coupled to ActiveRecord, which makes it hard to test in isolation and even harder to change safely. High test coverage numbers don’t fix that. You can have 80% coverage and still have every important decision buried in a callback on a 900-line model.
On the other hand, if I see a healthy app/services or a lot of plain Ruby objects scattered around, that’s a good sign. It means someone at some point made a deliberate choice to pull logic out of the models. The code isn’t necessarily cleaner, but the instinct was right.
cloc app/
bundle exec rubycritic app/
Raw SLOC sets the scale of what you’re dealing with. RubyCritic’s churn-vs-complexity visualization is where it gets useful: files in the upper-right quadrant (high churn, high complexity) are actively hurting the team every sprint.
Model Structure
This is the pass I always do manually, not just with tools. Walk the models directory deliberately: what are the god models, where are the callbacks concentrated, what does the association graph look like?
# active_record_doctor — run the full suite
bundle exec rails active_record_doctor:run
What to look for: missing unique indexes (race condition risk), wrong dependent: options (silent data corruption risk), integer PKs in old apps, and dangerous default_scope usage that quietly filters queries application-wide.
Then enable Bullet in development and browse the app. Count the N+1s on core pages.
Git History
Before I open any code, I run five git commands: churn hotspots, bus factor, bug clusters, commit velocity, and crisis patterns. Takes a few minutes and tells me which files to read first.
Test Suite
time bundle exec rspec
COVERAGE=true bundle exec rspec # with simplecov configured
Over 30 minutes is a crisis. Developers won’t run it locally, which breaks the feedback loop entirely. SimpleCov zero-coverage files are your fear map. Commented-out tests are the most honest signal in the codebase.
Using AI During the Audit
Once I have a read on the structure, I’ve started using AI to accelerate specific parts of the audit. I’ve been using thoughtbot’s rails-audit patterns recently. They have a Claude Code skill that automates the initial pass. A good starting point before you dig into the specifics. Feed it a god model and ask it to identify the distinct responsibilities. Useful for planning a decomposition. Use it to spot patterns across multiple models you’d take longer to see manually.
Here are a few prompts I’ve found useful:
God model decomposition:
This is a Rails model. List every distinct responsibility you can identify.
Group related methods together and suggest what each group might be extracted into.
Callback mapping:
List every callback in this file, what it does, and what other models or side
effects it might touch. Flag anything that looks like it could cause unexpected
behavior.
Test coverage gap analysis:
What are the ten most important things to test in this file, in priority order?
One caveat: AI doesn’t know what the business does. It can’t tell you whether the complexity in Order is accidental or load-bearing. That judgment is still yours.
For newer apps, I also look at whether they’ve picked up Hotwire/Turbo or are still running a legacy JS layer with Sprockets, and whether there’s a Dockerfile or Kamal config. Both ship with Rails 8 by default, so if they’re missing, that’s a signal.
Quick-Reference Command Sequence
# Security
bundle audit update && bundle audit check
bundle exec brakeman --format html -o brakeman_report.html
# Dependency age
bundle outdated
bundle exec bundle_report compatibility --rails-version=7.2
# SLOC + complexity
cloc app/
bundle exec rubycritic app/
# Routes — quick count before you open the file
bundle exec rails routes | wc -l
# Dead routes and orphaned actions
bundle exec traceroute
# Database
bundle exec rails active_record_doctor:run
# Memory
bundle exec derailed bundle:mem
# Test suite
time bundle exec rspec
COVERAGE=true bundle exec rspec
# When was the test suite last touched?
git log --oneline -1 -- spec/
Recoverable vs. In Trouble
The team is scared but they can still name what they’re scared of. Specific fear means they understand the system well enough to know where the bodies are buried. Deploys still happen, even if they’re painful. A team that ships, even reluctantly, is recoverable. There’s a test suite, even a bad one. Something is better than nothing. The god models are big but you can trace the logic. Messy doesn’t mean incomprehensible.
The harder conversation looks different. Nobody can explain how a core flow works without reading the code line by line. That’s not complexity. That’s lost knowledge. Deploys have stopped entirely because it’s too unpredictable. There are parts of the system with an unofficial “do not touch” status: not because they’re complex, but because nobody remembers why they work. The test suite takes 90 minutes and fails intermittently, so nobody runs it.
Sometimes the codebase isn’t the problem at all. The business has outgrown the architecture and no amount of cleanup will fix that. The rewrite question isn’t really about the code. It’s whether working around the problems costs more than starting over. Usually the answer is no, but when it’s yes, you feel it.
Signs you’re actually in trouble:
- Deploy frequency has dropped toward zero because “it’s too risky”
- Features quietly disabled, never re-enabled
- Multiple developers independently describe different parts as “nobody touches that”
- No APM, no error tracking, no alerting in production
- “I changed one thing and something completely different broke” is a regular occurrence
This rewrite-vs-refactor evaluation is the core of technical due diligence for acquisitions or investment rounds. It’s the question a buyer or investor most needs answered before committing. If you want a lighter-weight version of this assessment, try running a codebase drag audit first.
What the First Week Should Produce
Not a list of everything wrong. That just overwhelms people.
Early on, I wrote long reports. Exhaustive findings documents with every RuboCop violation, every outdated gem, every missing index. Color-coded spreadsheets. Clients would nod, say “very thorough,” and file it away. I realized I was putting the burden of prioritization back on them, which is exactly what they hired me to avoid.
What works better is a single page with three sections: fix this week, fix this quarter, don’t worry about it. I also call out a fourth category: things I can fix without touching your team’s current output. Dependency upgrades, security patches, dead code removal, and rewriting parts of the codebase that nobody owns and nobody wants to touch. Work that can happen in parallel without interrupting a sprint or stealing engineering time. Clients love knowing there’s a bucket of real progress that costs them nothing in team bandwidth.
A short verbal debrief before anything written, because the conversation matters more than the document. And leading with the one thing that surprised me most: not the longest list, the most important finding.
The thing that changed how I think about deliverables: I started asking myself “if this team could only fix one thing this year, what should it be?” It forces you to have an opinion, not just a list of observations. Clients hire you for the opinion.
- Severity triage: security/compliance risks that need immediate action, architectural problems slowing development, cosmetic issues that can be addressed over time
- The five highest-churn, lowest-coverage files: the specific things hurting the team right now
- Bus factor assessment: who are the single points of failure?
- Version upgrade path: what it would take, and what it’s costing them not to do it
- One honest conversation: the thing the team suspected but hadn’t said out loud
If you’re staring at a codebase like this and want a second opinion, this is what I do for a living.
Related Articles
- Rails default_scope: Why You Should Never Use It
- Ruby 3.2 Is EOL: What You Actually Need to Do
- Rails 7.2 to 8.1 Upgrade: What Actually Breaks and How to Fix It
- Rails: How to Use Greater Than/Less Than in Active Record where Statements
- Solved: Warning: Using the last argument as keyword parameters is deprecated